Build Chatbots: Your Own Multi-Document Assistant
Welcome to this tutorial where we’ll build a powerful chatbot to answer questions from various documents (PDF, DOC, TXT). I’ve used LangChain, OpenAI API, and Large Language Models from Hugging Face to create a question/answer pipeline, and employed Streamlit for crafting a user-friendly web interface. In this blog, I will introduce LangChain, a cutting-edge framework for developing applications using LLMs.
1. Single Document vs Multiple Documents
When dealing with a single document, whether it’s a PDF, Microsoft Word, or a text file, the process remains fairly straightforward. Extracting all the text from the document and feeding it into an LLM prompt like ChatGPT allows us to pose inquiries about the content. This method mirrors the conventional usage of ChatGPT.
However, the scenario becomes more intricate when handling multiple documents. Due to the token limits inherent in LLMs, we confront the challenge of not being able to ingest all the information from these documents in a single request. As a result, our strategy shifts toward sending only the pertinent information to the LLM prompt to circumvent this limitation. But the question arises: How do we isolate and retrieve only the relevant information from our multitude of documents? This is where embeddings and vector stores become pivotal.
2. Embeddings and Vector Stores
Embeddings and vector stores play a crucial role in distilling relevant information from multiple documents. These tools aid in transforming text into numerical representations that capture semantic relationships and contextual meanings. By converting textual information into high-dimensional vectors, we can effectively organize and index the content. This allows us to efficiently retrieve and present only the most relevant information to the LLM prompt, thereby overcoming the size limitation and ensuring that our queries are focused and contextually aligned.
3. Introduction to LangChain
LangChain emerges as a robust framework that equips us with potent tools and methodologies essential for harnessing the capabilities of Language Models (LMs) effectively. It simplifies the implementation of LMs, providing a more user-friendly interface that accelerates the creation of diverse applications leveraging these models. Moreover, LangChain can support various LMs, including those from Hugging Face, OpenAI API, and others.
1 | |
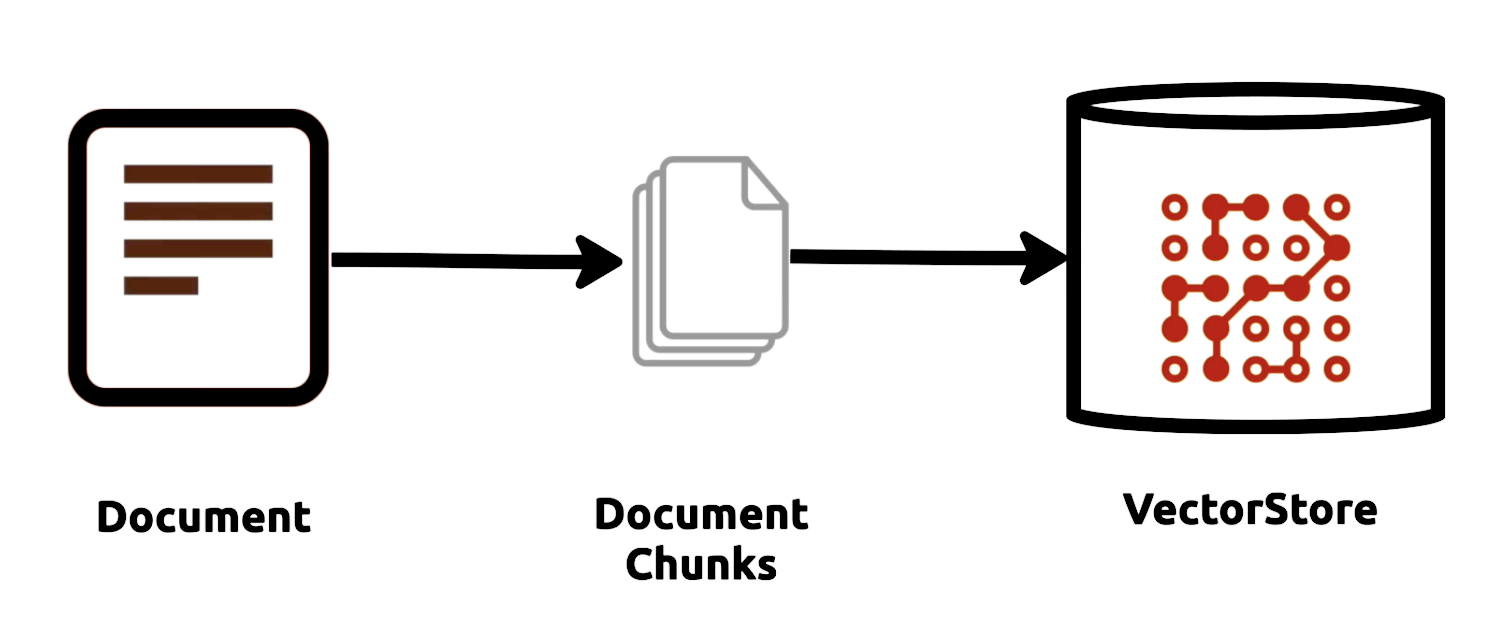
Text Splitter
The text_splitter module within LangChain, exemplified here by the CharacterTextSplitter class, provides a valuable utility for breaking down extensive text into manageable chunks. This functionality becomes particularly useful when dealing with large volumes of text, such as multiple documents, enabling efficient processing and analysis. The parameters defined within CharacterTextSplitter, including the separator, chunk size, and overlap, allow customization to suit specific requirements. By employing this module, developers can segment text intelligently, enhancing the overall workflow efficiency.
1 | |
Embeddings
The utilization of embeddings is integral to LangChain’s functionality. These embeddings capture the semantic nuances and contextual relationships within the text, enabling the generation of high-dimensional vectors that encapsulate the essence of the content. The choice of embeddings can significantly impact the performance of downstream tasks, and LangChain’s flexibility in accommodating various embedding methodologies ensures adaptability to diverse use cases. In our case, we use the OpenAI embeddings transformer, which employs the cosine similarity method to calculate the similarity between documents and a question.
Vector Stores
The vector store, exemplified by the FAISS class, serves as a repository for the high-dimensional vectors generated from the text chunks using the specified embeddings. This component enables efficient storage, indexing, and retrieval of vectors, optimizing the process of accessing relevant information. By organizing these vectors in a manner conducive to rapid search and retrieval, LangChain’s vector stores empower developers to efficiently navigate through vast volumes of textual data, retrieving targeted information while mitigating the challenges posed by token limits in Language Models.
1 | |
LLM Model Deployment
Let’s take OpenAI as an example. How do we integrate it into our LangChain?
1 | |
Additionally, we can provide context for the load_qa_chain function, which sends the prompt to OpenAI, resembling something similar to the following:
1 | |
This code snippet demonstrates how we can employ the LangChain framework to load the question-answering chain and utilize an LLM (in this case, OpenAI) to respond to queries based on provided documents.
4. Making the Chatbot Remember Conversation History
To elevate the capabilities of our chatbot, we can implement a feature that allows it to retain and recall previous conversation records.
LangChain provides the ConversationBufferMemory class to manage conversation history. This class effectively stores and retrieves dialogue records, passing the history to the model with each request.
1 | |
5. Streamlit for Web App Development
Streamlit simplifies web app development by enabling users to create interactive applications with ease. Here’s an overview of how you can build a web app using Streamlit:
Setting up Streamlit: Install Streamlit using
pip install streamlitand initialize your app withstreamlit run app.py.Creating the Interface:
- Use
st.write()to display text, charts, images, or other content. - Leverage interactive components like
st.button(),st.slider(), orst.text_input()for user interaction. - Utilize
st.sidebarto create a sidebar for additional controls or information.
- Use
Handling User Inputs:
- Capture user inputs using functions like
st.text_input()orst.file_uploader(). - Process and respond to user queries or actions based on the inputs received.
- Capture user inputs using functions like
Real-time Updates:
- Streamlit automatically updates the app in real-time as you modify the code, providing instant previews without manual refreshing.
Integration with Data Visualization:
- Integrate popular data visualization libraries such as Matplotlib or Plotly to visualize data within your app using
st.pyplot()orst.plotly_chart().
- Integrate popular data visualization libraries such as Matplotlib or Plotly to visualize data within your app using
Deployment:
- Streamlit offers straightforward deployment options for sharing your app, making it accessible to others via a URL.
Example:
1 | |
Streamlit’s simplicity and integration with Python make it an excellent choice for quickly building and deploying web apps, especially for data-driven applications.
6. Entire Code
1 | |
This code specifically handles text files (.txt). For PDF or DOC files, you’d need to utilize specific libraries to extract text content from them.
For PDF files, libraries like PyPDF2, pdfplumber, or PyMuPDF can be used to extract text content.
For DOC files, libraries such as python-docx, pywin32, or textract can assist in obtaining text content.
For example:
1 | |
Additionally, you need to input your OPENAI_API_KEY and HUGGINGFACEHUB_API_TOKEN in the .env file. You’ll also require an htmlTemplates.py. For specific project details, please refer to my Chatbot repository on GitHub (publicly available).
7. Running Examples
Open your terminal and input streamlit run followed by the file path. For instance, on my computer:
1 | |
This command starts the application by executing the file named app.py located at the specified file path.
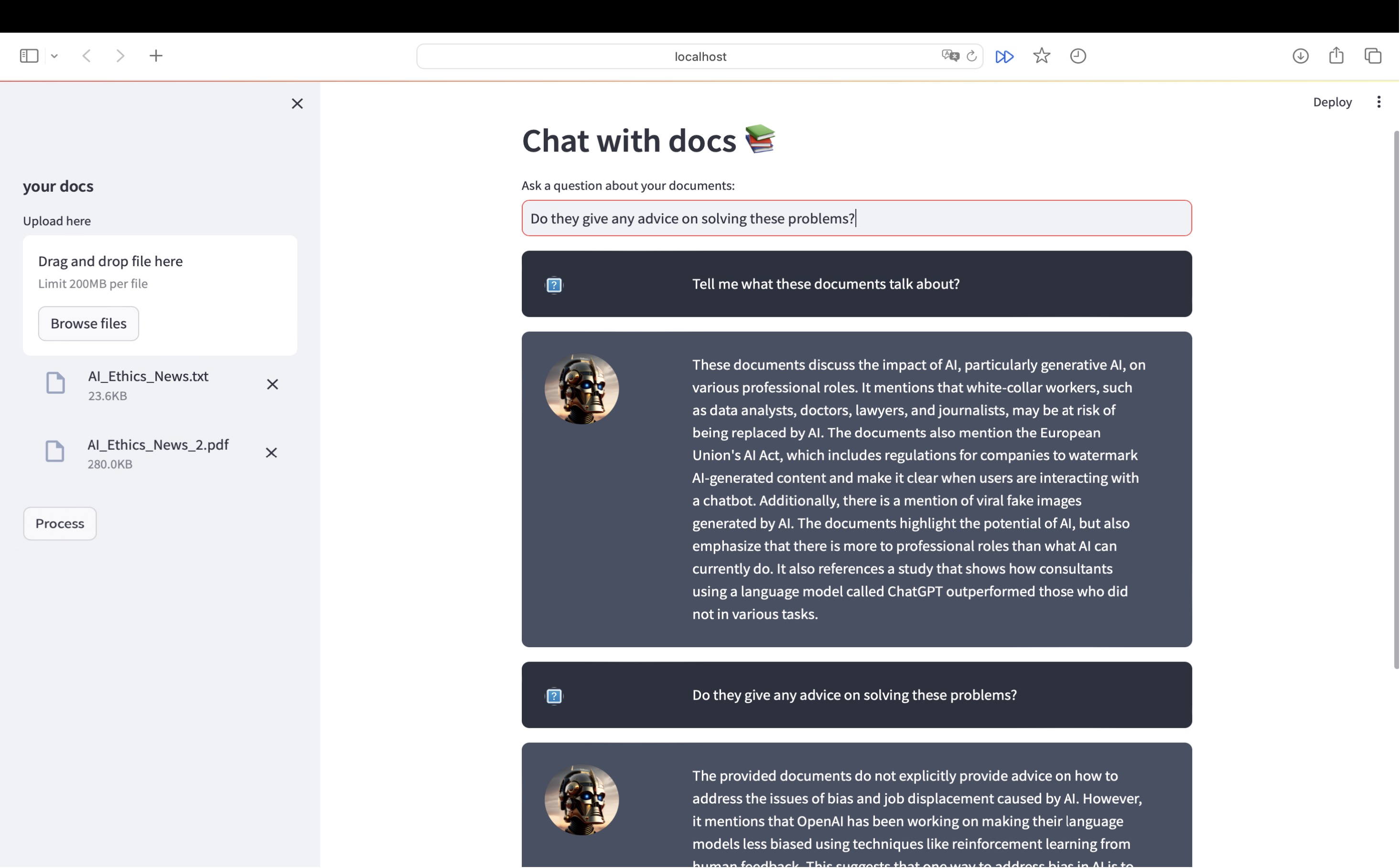
After uploading your files, click on the ‘Process’ button, then you can ask your questions!
This is a screenshot of my running example:
Happy coding!